

LSTM Variation
(For the PPT of this lecture Click Here)
Have you checked all our articles on Recurrent Neural Networks (RNNs)? Then you should be already pretty much comfortable with the concept of Long Short-Term Memory networks (LSTMs).
Let’s wind up our journey with a very short article on LSTM variations.
You may encounter them sometimes in your work. So, it could be really important for you to be at least aware of these other LSTM architectures.
Here is the standard LSTM that we discussed.
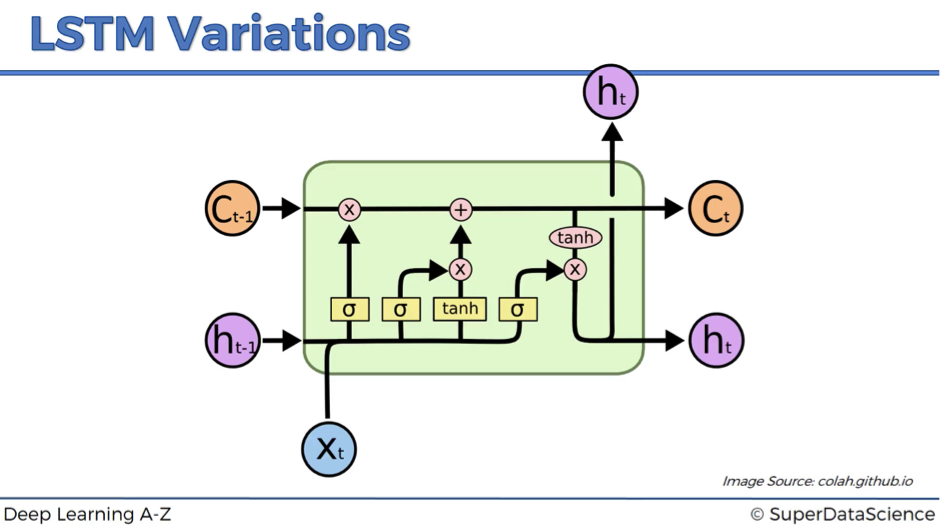
Now let’s have a look at a couple of variations.
Variation #1
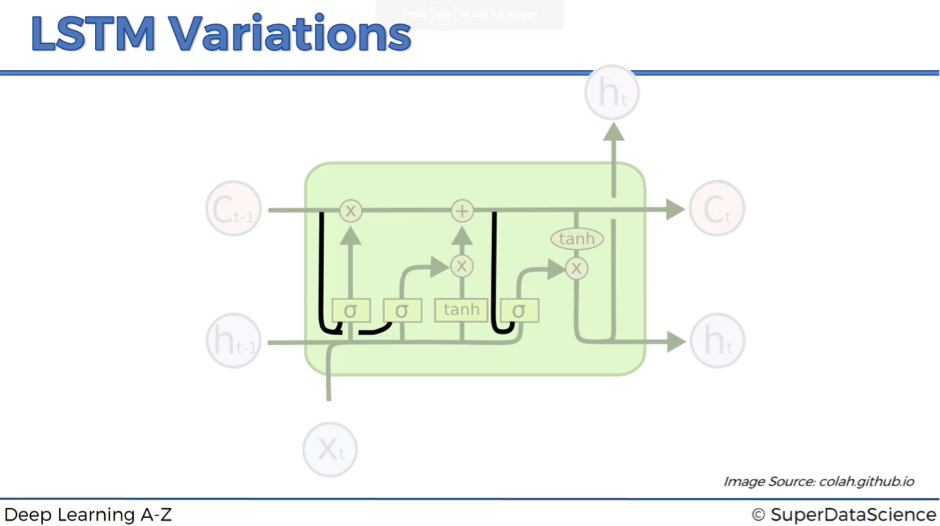
In variation #1, we add peephole connections – the lines that feed additional input about the current state of the memory cell to the sigmoid activation functions.
Variation #2
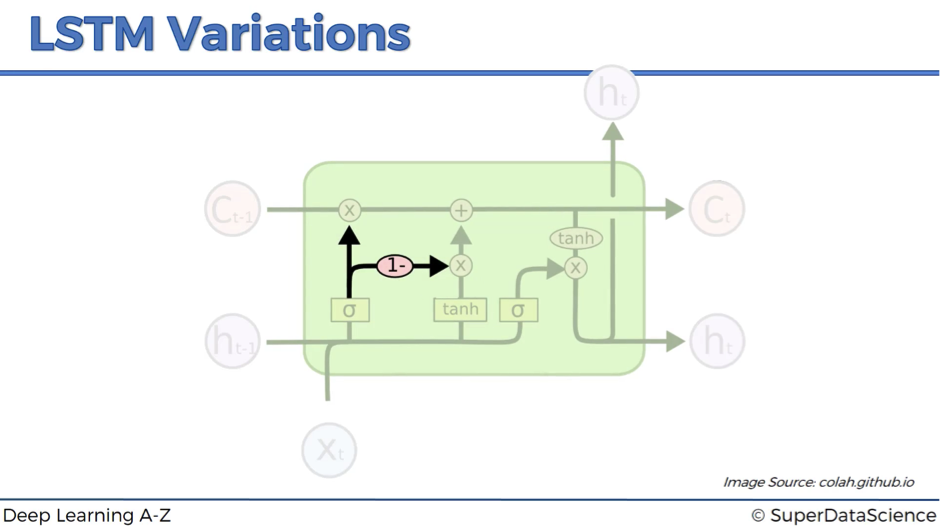
In variation #2, we connect forget valve and memory valve. So, instead of having separate decisions about opening and closing the forget and memory valves, we have a combined decision here.
Basically, whenever you close the memory off (forget valve = 0), you have to put something in (memory valve = 1 – 0 = 1), and vice versa.
Variation #3
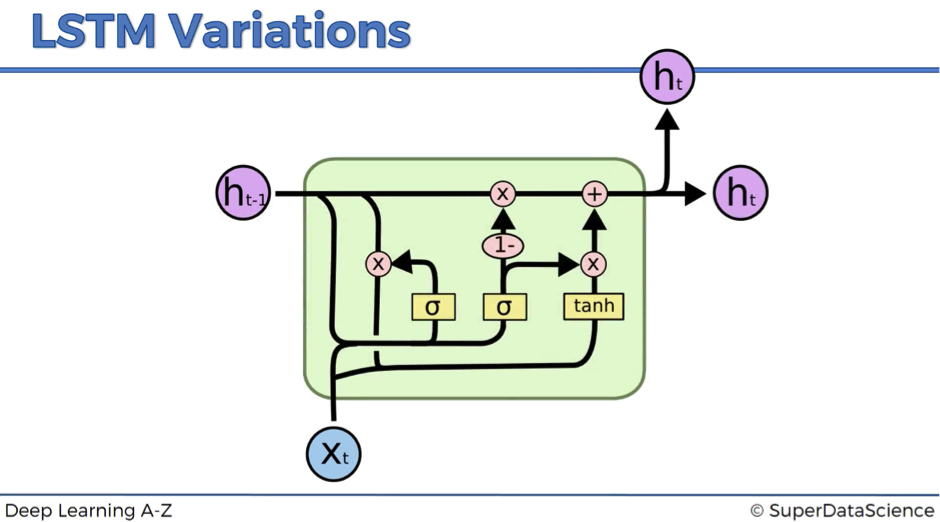
Variation #3 is usually referred to as Gated Recurrent Unit (GRU). This modification completely gets rid of the memory cell and replaces it with the hidden pipeline. So, here instead of having two separate values – one for the memory and one for the hidden state – you have only one value.
It might look quite complex, but in fact, the resulting model is simpler than the standard LSTM. That’s why this modification becomes increasingly popular.
We have discussed three LSTM modifications, which are probably the most notable. However, be aware that there are lots and lots of others LSTM variations out there.
Additional Reading
And finally, another good paper to check out:
- LSTM: A Search Space Odyssey by Klaus Greff et al. (2015)
This is a very good comparison of popular LSTM variants. Check it out, if interested!